音频领域有3A问题,所谓3A,是指声学回声消除(AEC,AcousticEchoCancel)、背景噪声抑制(ANS,AutomaticNoiseSuppression)、自动增益控制(AGC,AutomaticGainControl),今天聊一聊AEC。
什么是AEC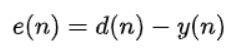
远端讲话者(A)的声音信号再传输给近端(B)后,在近端设备的扬声器播放出来,经过一系列声学反射,被近端设备的麦克风拾取,又传输给远端(A)的现象。声学回声将导致远端讲话者A在很短时间内,又听到了自己刚才的讲话声音。声学回声的产生过程如图所示。
使用AEC技术后,两端声音传输过程改变为如下图所示,进而从底层保证会议场景下声音的干净度。
数学化表示如下图。
远端信号x,从听筒或喇叭spk播出,并经过空间传播,被麦克风mic接收,近端说话信号也进入麦克风mic,这样麦克风接收到的就是两个信号的叠加,即d。自适应滤波器w对x进行处理获得y(回声信号),d和y的差值作为误差e,传递给自适应滤波器,进行滤波器系数迭代更新。
AEC性能评价指标指标1:ERLE(EchoReturnLossEnhancement,回声返回衰减增益):
ERLE值越大,则表明回声抵消效果越好。由于双讲或只有近端单讲时,e(n)中包含近端语音,导致很多情况下e(n)的能量远大于回声y(n)的能量,从而ERLE为负值,同时也无法衡量回声部分的消除情况。
对于优秀的回声消除器,ERLE增益必须不低于6dB。
指标2:SupperFactor(能量衰减因子)
AEC后输出能量与对应远端麦克风信号能量的比值。
指标3:Cohde(输出信号e(n)与麦克风信号d(n)的频谱相关性)
该值越接近1,说明输出信号中保留的麦克风信号频谱越多。考虑到麦克风信号d(n)主要由回声信号y(n)和近端语音v(n)构成,因此只有近端单讲情况下cohde的值才能接近1,双讲情况下cohde的值在0.5~0.9(取决于回声信号在该帧的占比),当cohde接近0时说明输出信号几乎不包含任何近端语音和回声的频谱成分。其计算公式如下:
指标4:Cohxe(输出信号e(n)与远端参考信号x(n)的频谱相关性)
该值越接近0,说明输出信号中残留的远端参考信号频谱越少,回声消除越彻底,其计算公式如下:
不同通话状态对应的参数指标:
(1)近端单讲(最大程度保持输出与麦克风信号一致):
Cohde:越接近1说明输出与麦克风信号越相似,越接近0说明两者差异越大,近端单讲时理想值为1。
Cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,近端单讲时理想值为1。
(2)远端单讲(最大程度抑制回声):
ERLE:值越大越好,则表明残留回声的能量相对值越小,回声抵消效果越好。
Cohde:越接近1说明输出与麦克风信号越相似,越接近0说明两者差异越大,远端单讲时理想值为0。
Cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,远端单讲时理想值为0。
(3)双讲(尽量抑制回声同时保留近端语音)
Cohde:越接近1说明输出与麦克风信号越相似,保留的近端语音频谱成分也越多;越接近0说明两者差异越大,保留的近端语音频谱成分也越少,双讲时理想值为0.5~0.9(取决于回声信号在该帧的占比)。
Cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,双讲时理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,双讲时理想值为1。
AEC技术原理典型回声消除技术框架如下图。
远端信号x从听筒或喇叭spk播出,并经过空间传播,被麦克风mic接收,近端说话信号也进入麦克风mic,这样麦克风接收到的就是两个信号的叠加,即d。自适应滤波器w对x进行处理获得y(回声信号),d和y的差值作为误差,传递给自适应滤波器,进行滤波器系数迭代更新。
远端参考信号(上图far-signal)经过自适应滤波器w
远端参考信号经过空间传播(即经过RoomImpulseResponse)得到x'
目标误差
其实,自适应滤波器的作用就是来抵消房间冲击响应对x的影响,以误差最小为目标。
具体算法:
(1)LMS(leastmeansquare)
LMS是最广泛应用的自适应滤波算法,以MSE误差为目标函数,以梯度下降为优化算法。NLMS是使用输入的功率对步长进行归一化的方法,可以取得更好的收敛性能。
算法复杂度:
LMS:(2M+1次乘法和2M次加法)*序列长度
NLMS:(3M+1次乘法和3M次加法)*序列长度
(2)BlockLMS
LMS算法对输入数据是串行处理的,可以通过将输入数据分段并行处理,类似深度学习领域的mini-batch操作,并且利用频域FFT来做快速卷积,大大减少计算复杂度。
首先需要将串行的LMS算法转变为分块处理,也就是BlockLMS(BLMS)。每次迭代,输入数据被分成长度为L的块进行处理。和LMS使用瞬时梯度来进行滤波器参数更新不同,BLMS使用L点的平均梯度来进行参数更新。对第k块数据,BLMS算法递推公式为:
(3)FastBlockLMS
思想是利用FFT进行助攻加速,称作FastBlockLMS,或FrequencyDomainAdaptiveFilter。对于长度为M的滤波器,一般采用2M点的FFT(M点补零),且使用overlap-and-save的快速卷积方法。
算法复杂度
10MlogM+26M
(4)PartitionedFastBlockLMS
对滤波器的时长进行分割,达到降低时延的目的。又称Multidelayblockfilter(MDF)。
如果将长度为M的滤波器等分成长度为B的小段,M=P*B。则卷积的结果可以分解为个P卷积叠加。
双讲检测存在远近端同时讲话场景,针对该场景,要进行双讲检查。
自适应滤波器有三种工作模式(通过DTD双讲检测):
远端语音存在,近端语音不存在:滤波、自适应滤波器系数更新
远端语音存在,近端语音存在:滤波
远端语音不存在:什么都不用做
Webrtc中的回声消除模块,已包含:双讲检测技术(语音活动检测,区分希腊佛中是否存在双端讲话)、自适应滤波技术(主要性能指标:跟踪性能、抗冲激性、鲁棒性和计算复杂性)、后处理(消除自适应滤波器的输出误差)。
双滤波器结构与双讲检测:
Speex除了使用MDF作自适应滤波,还是用了双滤波器结构(Two-PathMethod)。双滤波器结构包括一个迭代更新的自适应BackgroundFilter,和一个非自适应的ForegroundFilter。在自适应滤波器性能变坏、甚至发散时,AEC使用ForegroundFilter的结果,并且重置BackgroundFilter。在BackgroundFilter性能变好时,将其参数下载到ForegoundFilter。
这种双滤波器结构,可以实现隐式的双讲检测。在双讲的情况下,BackgroundFilter无法收敛,其更新结果不会保存下来,也就实现了区分双讲和非双讲的目标。
上图就是典型的双滤波器AEC结构,其核心就是将BackgroundFilter下载到ForegoundFilter的判决标准。一般而言,可以有着几方面的考虑:
SpeexAEC使用的判决准则,可以从代码里面提炼出来,跟以上提到的几点不完全一样,是用ForegroundFilter和BackgroundFilter输出的残留功率之差来进行判别,
其中是ForegroundFilter与麦克风信号之差的功率,是BackgroundFilter与麦克风信号之差的功率,Dbf是两个Filter输出信号之差的平方。于是判别公式可以写成
代码地址:
%Logicforupdatingtheforegroundfilter*/%Fortwotimewindows,computethemeanoftheenergydifference,aswellasthevariance*/VAR1_UPDATE=.5;VAR2_UPDATE=.25;VAR_BACKTRACK=4;MIN_LEAK=.005;=.6*+.4*(Sff-See);=.85*+.15*(Sff-See);=.36*+.16*Sff*Dbf;=.7225*+.0225*Sff*Dbf;update_foreground=0;%Checkifwehaveastatisticallysignificantreductionintheresidualecho*/%Notethatthisis*not*Gaussian,soweneedtobecarefulaboutthelongertail*/if(Sff-See)*abs(Sff-See)(Sff*Dbf)update_foreground=1;elseif(*abs()(VAR1_UPDATE*))update_foreground=1;elseif(*abs()(VAR2_UPDATE*()))update_foreground=1;
如果BackgroundFilter过于发散,则应该重置,可将其重置为ForegroundFilter。其MATLAB代码如下:
%Doweupdate?*/if(update_foreground)=0;=0;=0;=0;=;%Applyasmoothtransitionsoastonotintroduceblockingartifacts*/forchan=1:(_size+1:N,chan)=((_size+1:N).*(_size+1:N,chan))+((1:_size).*(_size+1:N,chan));elsereset_background=0;%Otherwise,checkifthebackgroundfilterissignificantlyworse*/if(-(Sff-See)*abs(Sff-See)VAR_BACKTRACK*(Sff*Dbf))reset_background=1;if((-*abs())(VAR_BACKTRACK*))reset_background=1;if((-*abs())(VAR_BACKTRACK*))reset_background=1;if(reset_background)%Copyforegroundfiltertobackgroundfilter*/=;%Wealsoneedtocopytheoutputsoastogetcorrectadaptation*/forchan=1:(_size+1:N,chan)=(_size+1:N,chan);(1:_size,chan)=(:,chan)-(_size+1:N,chan);See=Sff;=0;=0;=0;=0;自适应滤波器步长优化
上述讲解的滤波器步长固定,其实也可以将步长作为参数,把固定步长优化成可变步长,并且通过当前的各段信号,推导出最优步长。
主要是基于论文OnAdjustingtheLearningRateinFrequencyDomainEchoCancellationWithDouble-Talk.
下面摘录其中的主要结论。最优步长等于残余回声方差与误差信号方差之比
为了计算残留回声的功率,定义泄漏因子,取值在0~1之间
泄漏因子通过递归平均更新:
残留回声消除ResidualEchoCancellation自适应滤波器不能百分百消除回声,AEC的输出信号含有残留的回声信号,这个时候就需要一个Post-Filter,进行残留回声消除(ResidualEchoCancellation)。可以采用信号处理方法,也可以采用深度学习方法。
参考资料[1]
[2]
[3]Speex回声消除,简书







有限公司之全资子公司NVD与Reviver签署增资协议,以0.43271美元/股的价格认购其发行的D系列优先股")